












Apache Kafka is probably the most well-known in the world of event streaming platforms. While Kafka was initially developed as a messaging queue, LinkedIn saw scalability in the platform. They both created it and turned it into an open-source offering, leaving the messaging system roots in the past.
Apache Kafka offers a wide variety of use cases and is essential for the data pipelines of developers and operators worldwide. How, then, does the Apache Kafka platform work?
What are some key metrics and applications of Kafka? And how can it impact data streams? Here’s what you need to understand to learn more about varied Kafka topics.
The Basics of Apache Kafka
What is Apache Kafka, exactly? How exactly does this Java application work outside of a fault-tolerant event streaming platform? At its core, Kafka is a high-throughput and low-latency platform capable of handling large data streams and events in real time. Kafka was also developed to harness Hadoop more capably and with a degree of reliability.
These can include website activity, responses, and other real-time applications. The Apache Software Foundation initially developed Kafka but now it’s an aggregate of LinkedIn.
Kafka can utilize Kafka Connect as one of its connectors for external systems and offers Kafka Streams, a processing library built on the Java API.
The real-time analytics and confluent platform include fault tolerance and delivery guarantees. However, the real-time component helps Kafka stand out from the competition.
While other platforms and microservices can handle streams of messages and offer fault tolerance, they weren’t designed to be durable enough for real-time analytics.
Existing batch-based solutions often have considerable complications regarding data movement and replication which is another area of opportunity for Kafka to persist.
Where enterprise messaging and event systems couldn’t handle this topic, Kafka found solutions for its consumer group.
How Apache Kafka Works
Kafka generally looks and operates like a traditional publish-subscribe model. It incorporates confluent publishers and targets alongside stream processing.
Kafka also circumnavigates data loss in many workloads and all messages that Kafka develops can persist and are durable enough for replication.
This high availability offered by Kafka queries makes it a good fit for a real-time stream. One of the key components for the Kafka consumer is the data store or log which is critical for a high volume of data.
The log is a time-order data sequence and queue. The data can ultimately be anything crucial for big data. It also has a timestamp so the data can be time-ordered.
However, the Kafka broker isn’t your traditional message broker. The Kafka broker doesn’t come with many additional bells, whistles, or new features that a group may expect from a messaging system. The analytics of Kafka doesn’t include message IDs; offset only addresses the messaging system.
This offset is found in the log. Kafka also doesn’t sync up who or what consumes the given messages in a queue. However, since it dramatically differs from a standard broker, it can offer some values that a broker can’t.
It lightens database loads without deleting within the client library or the log and can efficiently utilize an operating system for caches.
As such, the speed and scalability offered by the compaction of Kafka make it nearly invaluable for web-scale enterprises and organizations.
Here’s How Developers Can Make Use of Kafka Capabilities
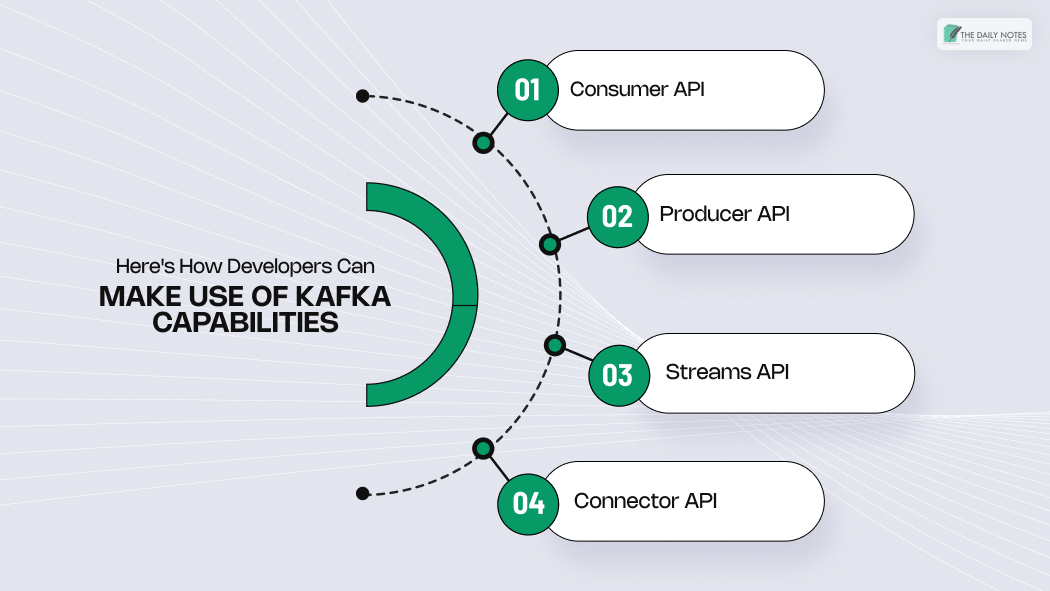
Developers can leverage these Kafka capabilities with the help of the following four KPIs:
- Consumer API: The consumer API enables an application to subscribe to one or more topics. This is helpful when ingesting and processing the topic-stream is necessary.
- Producer API: A Kafka topic is a log named after the record as it comes. The producer API allows the developer to allow an application to publish a stream to the topic.
The written record is permanent and remains on the topic for a set time or until storage runs out. - Streams API: Built on the producer and consumer APIs, the streams API adds a complex processing capability that enables an application to perform front-to-back, continuous stream processing. This enables the development of more sophisticated events and data-streaming applications.
- Connector API: The developers use it to build connectors that are reusable consumers or producers. These will simplify and automate the data source integration into a Kafka cluster.
RabbitMQ vs Apache Kafka
A very popular open-source message broker, RabbitMQ is a popular middleware that allows applications, services, and systems to communicate with each other. It allows the translation of messaging protocols between the systems or services.
However, Apache Kafka began as a message broker and is now primarily a stream-processing platform. However, it differs from RabbitMQ in its capacity. Kafka finds its use case in big data migration – moving data in high volumes.
Whereas RabbitMQ is perfect for low-latency message delivery. So, picking one out of the two is difficult as they are not alternatives to each other. Their choice depends on the requirement – if you have data with huge volumes, Apache Kafka should be your pick.
Apache Kafka in applications allows publishing, consuming, and processing record streams in high volumes. It does so in a durable and fast manner.
On the other hand, RabbitMQ is a message broker that allows applications to use different messaging protocols for sending and receiving messages to one another.
Event Streaming Made Easy!
From the Kafka Connect functionality to Kafka Clusters, Apache Kafka has impacted event streaming for the foreseeable future. With data replica capability and fault tolerance, only time will tell how Kafka continues to develop.
The replication and partitioning of Kafka topics is in a way that makes high-scaling up to higher volumes easy! Developers can use Apache Kafka record and generate streams of their own!
Using Kafka helps improve the quality of moving data. There’s better protection against duplication, corruption, or other problems with high-volume data migration.
Read Also:

















